使用Ragas评估LLM应用
使用Ragas评估LLM应用
说明
对于已知问题有正确答案的场景,适合使用 ragas 的 faithfulness 指标对 GenAI 应用响应结果进行评估,方便进行回归测试。
注意:本文提到的方法,只适用于对已知问题的评估。对于线上运行时,用户提的随机的、不在测试集范围内的问题,不适合用此方法评估。
安装
pip install ragas
数据说明
对以下数据进行评估。
事实:Einstein was born in 1879 in Germany.
提问:
- When did Einstein born?
- Where did Einstein born?
正确答案:
- Einstein was born in 1879.
- Einstein was born in Germany.
正确性❌
from dotenv import load_dotenv
load_dotenv()
from datasets import Dataset
from ragas.metrics import answer_correctness
from ragas import evaluate
data_samples = {
'question': [
'When did Einstein born?',
'Where did Einstein born?',
],
'answer': [
'Einstein was born in 1879.',
'Einstein was born in Germany.',
#'Einstein was born in 1879 in Germany.'
],
'ground_truth': [
'Einstein was born in 1879 in Germany.',
'Einstein was born in 1879 in Germany.',
]
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[answer_correctness])
print(
score.to_pandas()
)

这是不能令人满意的——正确的回答,得到的指标分数却不足0.8。
这是因为,正确性的评估,还依赖了相似度。
忠实度✔
from dotenv import load_dotenv
load_dotenv()
from datasets import Dataset
from ragas.metrics import faithfulness
from ragas import evaluate
data_samples = {
'question': [
'When did Einstein born?',
'Where did Einstein born?',
],
'answer': [
'Einstein was born in 1879.',
'Einstein was born in Germany.',
#'Einstein was born in 1879 in Germany.'
],
'contexts': [
['Einstein was born in 1879 in Germany.'],
['Einstein was born in 1879 in Germany.'],
]
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[faithfulness])
print(
score.to_pandas()
)

符合预期,满足要求!
实战演示
准备好样例问题
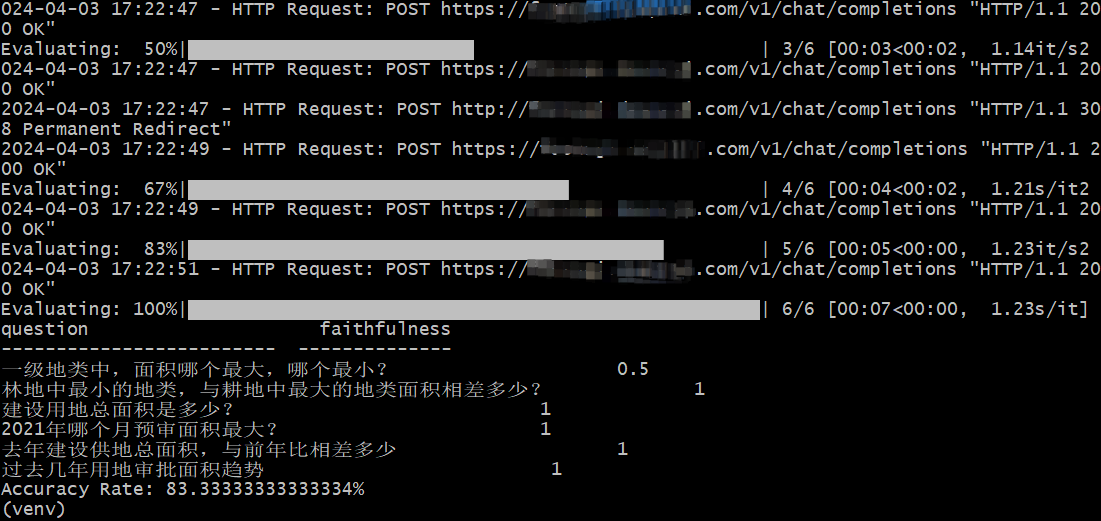
sample_questions = [
'一级地类中,面积哪个最大,哪个最小?',
'林地中最小的地类,与耕地中最大的地类面积相差多少?',
'建设用地总面积是多少?',
'2021年哪个月预审面积最大?',
'去年建设供地总面积,与前年比相差多少 ',
'过去几年用地审批面积趋势',
]
准备好正确答案
ground_truths = [
'一级地类中面积最大的是林地,面积为1609.53万公顷;面积最小的是湿地,面积为12.72万公顷。',
'林地中最小的地类是竹林地,面积为38.55万公顷。耕地中最大的地类是旱地,面积为167.17万公顷。它们的面积差距为167.17 - 38.55 = 128.62万公顷。',
'建设用地总面积为132.86万公顷。',
'2021年预审面积最大的月份是12月,预审面积为15875.50公顷',
'去年建设供地总面积为26,883.06公顷,前年建设供地总面积为29,670.19公顷。两年的差值为2,787.13公顷。',
'2021年的用地审批面积为57147.14公顷, 2022年的用地审批面积为50901.37公顷, 2023年的用地审批面积为17408.21公顷',
]
编写回答函数
async def get_answer_from_ai(question: str) -> str:
# 填充你的程序逻辑
进行答案评估
async def evaluation():
llm_answers = []
for i in range(len(sample_questions)):
llm_answers.append(await get_answer_from_ai(sample_questions[i]))
data_samples = {
'question': sample_questions,
'answer': llm_answers,
'contexts': list(map(lambda x: [x], ground_truths))
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset, metrics=[faithfulness])
result_df = score.to_pandas()[['question', 'faithfulness']]
result_table = result_df.values.tolist()
print(tabulate(result_table, headers=result_df.columns, tablefmt='simple'))
print(f"Accuracy Rate: {result_df['faithfulness'].eq(1).sum()/len(sample_questions) * 100}%")
if __name__ == '__main__':
asyncio.run(evaluation())
效果如下: